
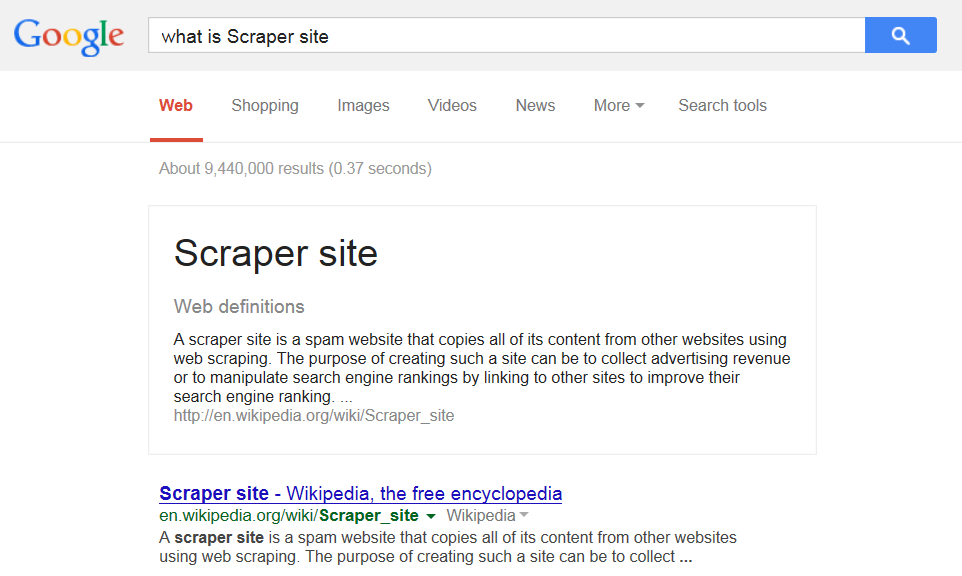
Scraper site je stránka, která kopíruje obsah anebo jen jeho části z jiné stránky či i několika stránek naráz. Vše se provádí automaticky a účelem není nic jiného než získat obsah, který by vyhledávače indexovali. Díky rozsáhlému linkbuidlingu, pak takovéto stránky dokáží přeskočit i originální v SERP. Což je velice nepříjemné a špatně se s tím bojuje. Cílem je většinou vydělávat na reklamě anebo sbírat linkjuice. Více informací o scraper site se můžete dozvědět na Seopedii.
Matt Cutts se rozhodl, že dá možnost lidem takovéto weby hlásit přes speciální formulář. Vzhledem k tomu, že se v poslední době párkrát pochlubil jak „rozprášili“ s antispamovým týmem nějaký blog network, tak se spíše domnívám, že tento formulář je tu z jiného důvodu.
Scraper sites jsou většinou na nižších stupních odkazových pyramid. Přeci jen, když potřebujete přes něco proprat desítky tisíc nekvalitních zpětných odkazů, tak potřebujete stovky webů s alespoň nějakým obsahem. Pokud se jim podaří tyto stupně odhalit dostanou se přes ně výše. Teoreticky můžou odhalit velkou část celé struktury.
Podle mě tedy nejde o nic jiného, jen získat tipy na weby zapojené do velkých link networků. Takže pokud doufáte, že přes tento formulář potrestáte kopírovače vašich článků, konkurenci, co vám krade originální texty z vašeho eshopů, tak to zřejmě nebudete fungovat.
Související články
Google najde a identifikuje více jak 25 miliard spam stránek každý den
P?ed pár dny Google vydal na svém blogu pro webmastery zprávu o tom jak bojoval se spamem a dalším závadným obsahem v roce 2019. A?koliv je…
Google vládne v USA vyhledávání a jeho pozice je nejsiln?jší jaká kdy byla
Podle Digital Marketing Report za Q3 2018 od spole?nosti Merkle narostl meziro?n? po?et návšt?v z organického hledání v USA z Google o 9 %. V…
Opravdu Google „krade“ návšt?vnost Wikipedii?
Nejen na SEO magazínech se probírá téma upadající návšt?vnosti Wikipedie z Google. N?co nastartoval ?lánek z konce ?ervence Is Wikipedia…
